
Τα μεγάλα γλωσσικά μοντέλα (LLM) έχουν φέρει επανάσταση στον τομέα της τεχνητής νοημοσύνης, ανοίγοντας νέες ευκαιρίες για εφαρμογές έρευνας και βιομηχανίας.
Έχει αποδειχθεί ότι τα LLM ανοιχτού κώδικα είναι ανταγωνιστικές εναλλακτικές λύσεις σε εμπορικές λύσεις και η χρήση τους μπορεί να προσφέρει υψηλότερο επίπεδο ελέγχου στην ανάπτυξη ασφαλών και βελτιστοποιημένων για εφαρμογές μοντέλων.
Ωστόσο, λόγω του τεράστιου όγκου των απαιτούμενων δεδομένων, τα περισσότερα ανεπτυγμένα ανοιχτά LLM έχουν εκπαιδευτεί σε τεράστια, κυρίως αγγλικά, μονόγλωσσα σύνολα δεδομένων (π.χ. Dolma), περιορίζοντας την απόδοσή τους σε άλλες γλώσσες.
Πρόσφατα, έγιναν προσπάθειες να επεκταθούν οι δυνατότητες των ανοιχτών LLM σε άλλες γλώσσες (π.χ. LeoLM για γερμανικά, Aguila f για ισπανικά κ.λπ.).
Προς αυτή την κατεύθυνση αναπτύχθηκε και κυκλοφόρησε από το Ινστιτούτο Επεξεργασίας Γλώσσας και Λόγου του Κέντρο Έρευνας & Καινοτομίας Αθηνά. το Meltemi LLM για την ελληνική γλώσσα. Το Meltemi αναπτύσσεται ως δίγλωσσο μοντέλο, διατηρώντας τις δυνατότητές του για την αγγλική γλώσσα, ενώ επεκτείνεται για να κατανοεί και να δημιουργεί άπταιστα κείμενο στα Νέα Ελληνικά χρησιμοποιώντας τεχνικές αιχμής.
Το Meltemi είναι χτισμένο πάνω στο LLM ανοιχτού λογισμικού της Mistral-7B και έχει εκπαιδευτεί σε ένα corpus ελληνικών κειμένων υψηλής ποιότητας. Υπάρχουν δύο παραλλαγές του Meltemi στην έκδοση 1k: το θεμελιώδες μοντέλο Meltemi-7B-v1 και το παράγωγό του, Meltemi-7B-Instruct-v1 που μπορεί να χρησιμοποιηθεί για εφαρμογές συνομιλίας
Και τα δύο μοντέλα κυκλοφορούν υπό την ανοιχτή άδεια χρήσης άδεια Apache 2.0 όπως και το Mistral.
Η εκπαίδευση των μοντέλων πραγματοποιήθηκε σε υποδομή AWS χάρη σε επιχορήγηση του ΕΔΥΤΕ.
Η αρχική έκδοση του Mistral-7Β εκπαιδεύτηκε σε ένα μεγάλο σώμα αγγλικού κειμένου. και στην συνέχεια επεκτάθηκε η προπαίδευση του Mistral-7Β με πρόσθετη επάρκεια στην ελληνική γλώσσα, αξιοποιώντας ένα μεγάλο σώμα που αποτελείται από περίπου 40 δισεκατομμύρια tokens. Αυτό το σώμα περιλαμβάνει 28,5 δισεκατομμύρια ελληνικά tokens, κατασκευασμένα από διαθέσιμους πόρους στο κοινό. Επιπλέον, για να να διασφαλιστεί ότι το μοντέλο έχει δίγλωσσες δυνατότητες, χρησιμοποιήθηκαν επιπλέον υποσώματα με 10,5 δισεκατομμύρια tokens αγγλικών κειμένων και ένα παράλληλο σύνολο δεδομένων ελληνοαγγλικών 600 εκατομμυρίων tokens.
Αυτό το σώμα έχει υποβληθεί σε επεξεργασία, φιλτράρισμα και κατάργηση των αντιγράφων για τη διασφάλιση της ποιότητας των δεδομένων (μια λεπτομερής περιγραφή του αγωγού επεξεργασίας δεδομένων μας θα δημοσιευθεί στο επόμενο αργότερα).
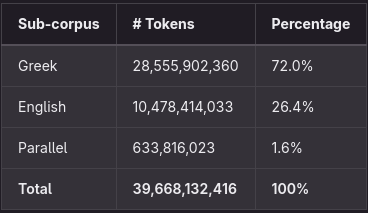
Πίνακας 1: Σώμα προπαίδευσης
Για να δημιουργηθεί το Meltemi-7B-Instruct-v1, χρησιμοποιήθηκαν περίπου 100.000 ελληνικές οδηγίες, οι οποίες περιλαμβάνουν μηχανικά μεταφρασμένες εκδόσεις των υπαρχόντων συνόλων δεδομένων συνομιλίας μίας στροφής και πολλαπλών στροφών. Συγκεκριμένα χρησιμοποιήσαμε τα εξής:
- Open-Platypus (μόνο υποσύνολα με επιτρεπτές άδειες)
- Evol-Instruct
- Capybara
- Ένα ελληνικό σύνολο δεδομένων που δημιουργήθηκε με μη αυτόματο τρόπο με παραδείγματα πολλαπλών στροφών που κατευθύνουν το συντονισμένο με οδηγίες μοντέλο προς ασφαλείς και αβλαβείς αποκρίσεις
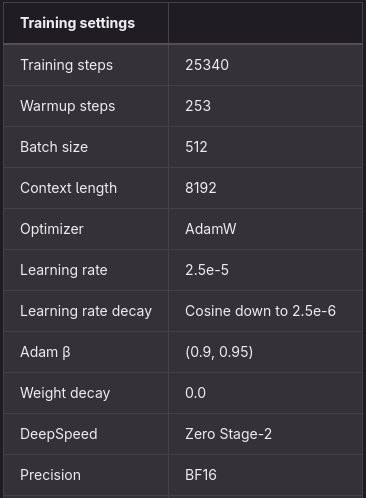
Το μοντέλο εκπαιδεύεται στις οδηγίες που προκύπτουν με τη χρήση εποπτευόμενου μικροσυντονισμού (SFT). Η διαδικασία SFT βασίζεται στις τελειοποιημένες μεθόδους που παρέχονται από το Hugging Face:
- Όλα τα σενάρια εκπαίδευσης και λεπτομέρειας, καθώς και το fork lm-evaluation-harness θα διατίθενται στο κοινό με ανοιχτή άδεια χρήσης BSD-like
- Διαβάστε περισσότερα στο https://medium.com/institute-for-language-and-speech
- Δείτε τον κώδικα του Meltemi-7B-v1 και του Meltemi-7B-Instruct-v1 στο https://huggingface.co/ilsp